2.1 KiB
2.1 KiB
- 20260622 only for vllm/vllm-openai:gemma container
serve
sudo docker run --rm -it --name=vllm-diffusiongemma --gpus all --runtime=nvidia --ipc=host --network host \
--shm-size=16g --ulimit memlock=-1 --ulimit stack=67108864 \
-e NVIDIA_VISIBLE_DEVICES=nvidia.com/gpu=all \
-e LD_PRELOAD=/usr/lib/aarch64-linux-gnu/nvidia/libcuda.so.1 \
-e LD_LIBRARY_PATH=/usr/lib/aarch64-linux-gnu/nvidia:/usr/lib/aarch64-linux-gnu:$LD_LIBRARY_PATH \
-e VLLM_USE_V2_MODEL_RUNNER=1 \
-v ~/thor/root:/root \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v ~/thor/thor-vllm-cache:/root/.cache/vllm \
-v ~/thor/thor-torch-cache:/root/.cache/torch \
-v ~/thor/ws:/workspace/ws \
-v ~/thor-wm:/workspace/thor-wm \
-v ~/WorkspaceMl:/workspace/wsml \
vllm/vllm-openai:gemma \
--model "/workspace/thor-wm/nvidia-diffusiongemma-26B-A4B-it-NVFP4" \
--port "8002" \
--host "0.0.0.0" \
--served-model-name "nvidia/diffusiongemma-26B-A4B-it-NVFP4" \
--max-model-len 262144 \
--tensor-parallel-size 1 \
--max-num-seqs 8 \
--gpu-memory-utilization 0.01 \
--kv-cache-memory-bytes 9g \
--attention-backend TRITON_ATTN \
--enable-auto-tool-choice \
--tool-call-parser gemma4 \
--reasoning-parser gemma4 \
--override-generation-config '{"max_new_tokens": null}' \
--mm-processor-kwargs '{"max_soft_tokens": 1120}' \
--limit-mm-per-prompt '{"image": 7}'
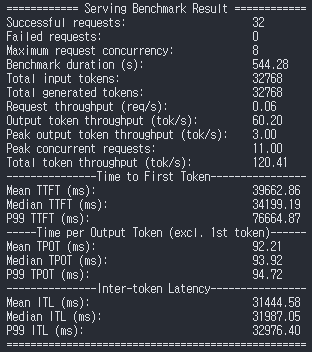
bench
vllm bench serve \
--model "/workspace/thor-wm/nvidia-diffusiongemma-26B-A4B-it-NVFP4" \
--served-model-name "nvidia/diffusiongemma-26B-A4B-it-NVFP4" \
--host localhost \
--port 8002 \
--dataset-name random \
--random-input-len 1024 \
--random-output-len 1024 \
--num-prompts 5 \
--max-concurrency 1
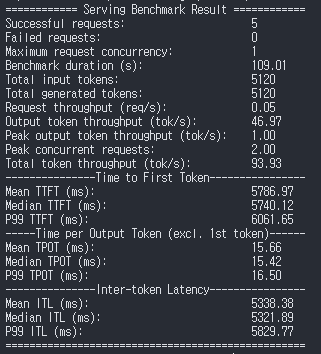
vllm bench serve \
--model "/workspace/thor-wm/nvidia-diffusiongemma-26B-A4B-it-NVFP4" \
--served-model-name "nvidia/diffusiongemma-26B-A4B-it-NVFP4" \
--host localhost \
--port 8002 \
--dataset-name random \
--random-input-len 1024 \
--random-output-len 1024 \
--num-prompts 32 \
--max-concurrency 8